

Streamlining and Securing Access
to DevOps Resources
Introduction
As the DevOps methodology takes hold within organizations all over the world, there are a number of implications that IT and ops teams are grappling with – none more critical than identity management. Securely connecting to all of the new types of DevOps focused solutions is a critical part of effectively managing modern IT infrastructure.
This is the question DevOps teams keep asking us:
“Is it possible to unify identity management across all DevOps infrastructure while meeting rigorous standards in security?”
DevOps is fast-moving, platform independent, and forward-thinking by definition. It makes perfect sense that IT and ops personnel would seek out solutions that match their high-expectations for efficiency, compatibility, and security.
The short answer to the question is “Yes” – and we’ll explain that as we share our simple blueprint for “DevOps Identity Management in a Box” below.
The State of Identity in DevOps
DevOps methodology is pushing the boundaries of IT architecture and creating a wealth of new opportunities for IT and DevOps teams.
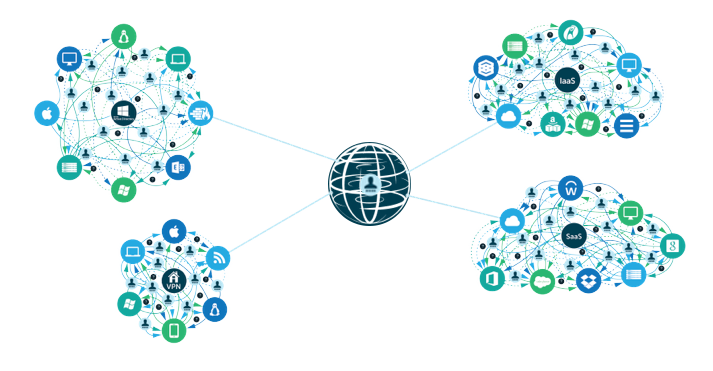
- On-prem servers and data centers are no longer required. Production infrastructure can be 100% cloud-hosted. This means that the ops team no longer needs to purchase, install, and maintain all of the equipment.
- Infrastructure-as-a-Service platforms such as AWS have revolutionized the ability for engineers to manage large infrastructure through code, allowing them to specialize on their product or service, not specialize on managing servers.
- A recent wave of Software-as-a-Service solutions has changed the game on the development and deployment process. Tools such as GitHub, Atlassian, Docker, and Jenkins have revolutionized the way developers write, store, test, and deploy their code. Modern SaaS and on-prem monitoring solutions are providing ops organizations with more data and insight into how their platforms and applications are performing.
- The emergent Directory-as-a-Service® is centralizing access to DevOps infrastructure and unifying an identity across IaaS, SaaS tools, and existing user directories like Active Directory®, OpenLDAP™, G Suite, and Office 365.
While there is no doubt that DevOps processes are more than just infrastructure and tools, these solutions have become a core part of implementing the methodology.
“It is not the strongest of the species that survive, nor the most intelligent, but the one most responsive to change.”
-Charles Darwin
DevOps Identity Requirements
Many organizations that are leveraging DevOps are also typically progressive thinking, cloud-forward organizations leveraging a wide variety of cloud-based platforms and providers. It isn’t surprising that DevOps teams are also forward thinking about their IT infrastructure.
So while Microsoft Active Directory® may be part of the identity management strategy at your organization, there’s a good chance that DevOps isn’t the team that put it there.
DevOps inherently thinks of the identity in terms of virtual environments.
The result is that teams want their G Suite or Microsoft Office 365 credentials to also be those that they leverage to access AWS cloud servers (and the IAM console), GitHub, Docker, Jenkins, and much more – a central identity that can be easily provisioned and de-provisioned as needed.
Security
Adaptable. Compatible. Streamlined.
These words are as good as gold for fast-moving DevOps teams. Cross-platform independence is imperative. Efficiency at the onset will save long hours of coding in the long run.
But security still comes first.
A fully secured identity lays the foundation for a fully secured organization. An insecure identity can undermine the most advanced security measures put into place in the outer circles of organizational security.
Identity security has become the core of IT security.

This is why it is integral that data is stored with deep encryption practices both in transit and when at rest. It is through these types of advanced DevOps security practices that cloud identity management now often exceeds on-prem IAM when it comes to security standards.
That same core identity needs to be able to leverage both their associated SSH keys where applicable and multi-factor authentication for increased security.
DevOps Identity Management in a Box
Developers and ops engineers often need to spend a great deal of time onboarding/offboarding accounts, or managing SSH keys and MFA tokens for existing users.
The way to remedy this is to unify the management of the identity. Everything the DevOps admin needs to manage should all fit in one “box” (or screen). This is the easy way to connect a single identity across AWS, GitHub, Docker, Jenkins, NewRelic, and much more.
Below, we’ll explain how you can simplify and secure your approach to DevOps with a cross-platform, 100% cloud-based system we call “DevOps Identity Management in a Box.”
The Main Ingredient: Cloud-based IAM
It’s no surprise that the best way for DevOps teams to manage their identity management and access issues comes from the cloud.
Many critical DevOps solutions are cloud-based, so it is only logical that their identity management would be designed for the cloud era, from the ground up.
Directory-as-a-Service®
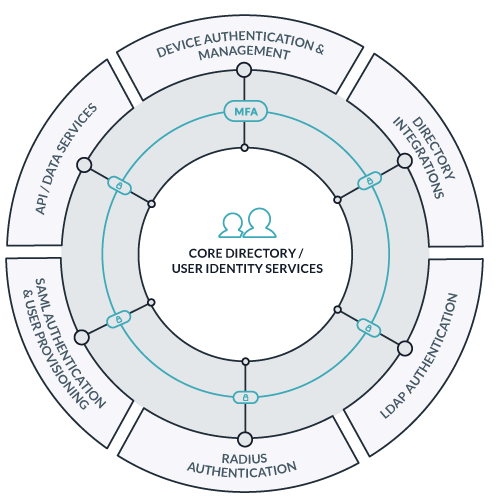
The latest wave of ______-as-a-Service to spur innovation in the world of DevOps is Directory-as-a-Service (DaaS). This cloud-based identity management platform is often considered to be the reimagination of Microsoft Active Directory or LDAP for the DevOps era.
DaaS is automating and simplifying the process of running technical organizations and infrastructure. Admins get elegant identity management – all from one pane of glass.
JumpCloud’s Directory-as-a-Service securely manages and connects user identities to:
- Mac, Linux or Windows workstations
- Cloud or on-prem servers (e.g. Linux or Windows servers on AWS, Google Cloud Platform, Azure, etc.)
- Web or on-prem applications such as Atlassian, Docker, GitHub, PagerDuty, NewRelic, OpenVPN, and thousands of others
- Storage infrastructure, and networking gear including WiFi networks
DevOps admins achieve centralized control over their users, while stripping away the need to configure and manage infrastructure.
Cloud Directory Protocols and Architecture
Multi-Protocol Versatility
JumpCloud supports LDAP, SSH, SAML 2.0,, RESTful APIs, and RADIUS in order to ensure connectivity with a wide variety of IT resources. Watch our whiteboard video on JumpCloud’s protocols and architecture for a deeper understanding.
Platform Independence
Directory-as-a-Service is a True Single Sign-On™ platform cutting across systems, applications, infrastructure, and networks.
Cloud-Forward Security
JumpCloud doesn’t store a plaintext password. All of the data we store is one-way hashed and salted. Unlike many on-prem directories, all data with JumpCloud is encrypted both in transit and at rest, to ensure a breach-resistant security posture. See our security page.