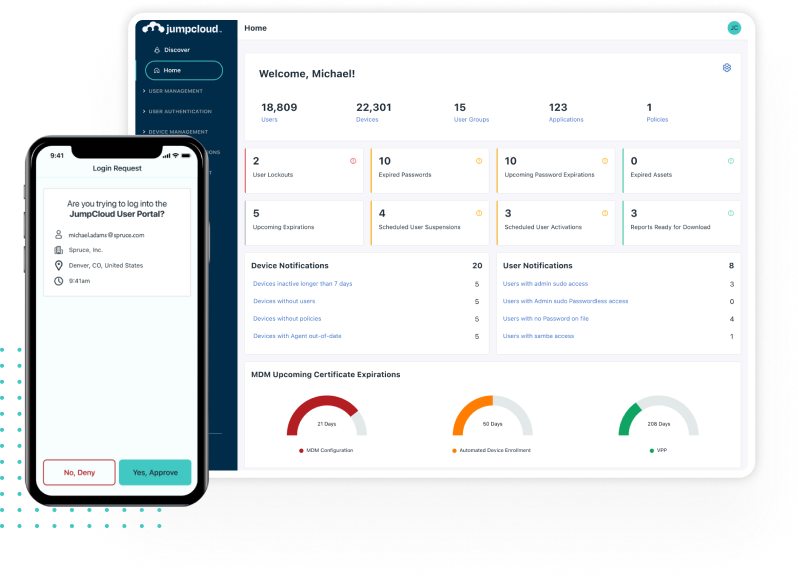
Secure, Frictionless Device & Identity Management
Fully Integrated Identity Lifecycle with MFA, MDM, Patch Management, & System Insights Across OSs -- Apple, Windows, & Linux 
Secure, Frictionless Device & Identity Management
Fully Integrated Identity Lifecycle with MFA, MDM, Patch Management, & System Insights Across OSs -- Apple, Windows, & Linux
What's New
eBook
State of IT 2024: The Rise of AI, Economic Uncertainty, and Evolving Security Threats
Learn MoreWhitepaper
Modernizing Active Directory: Eliminate IT Complexity and Extend Support to Non-Microsoft Resources
Learn MoreSecure, Frictionless Device & Identity Management
Fully Integrated Identity Lifecycle with MFA, MDM, Patch Management, & System Insights Across OSs -- Apple, Windows, & Linux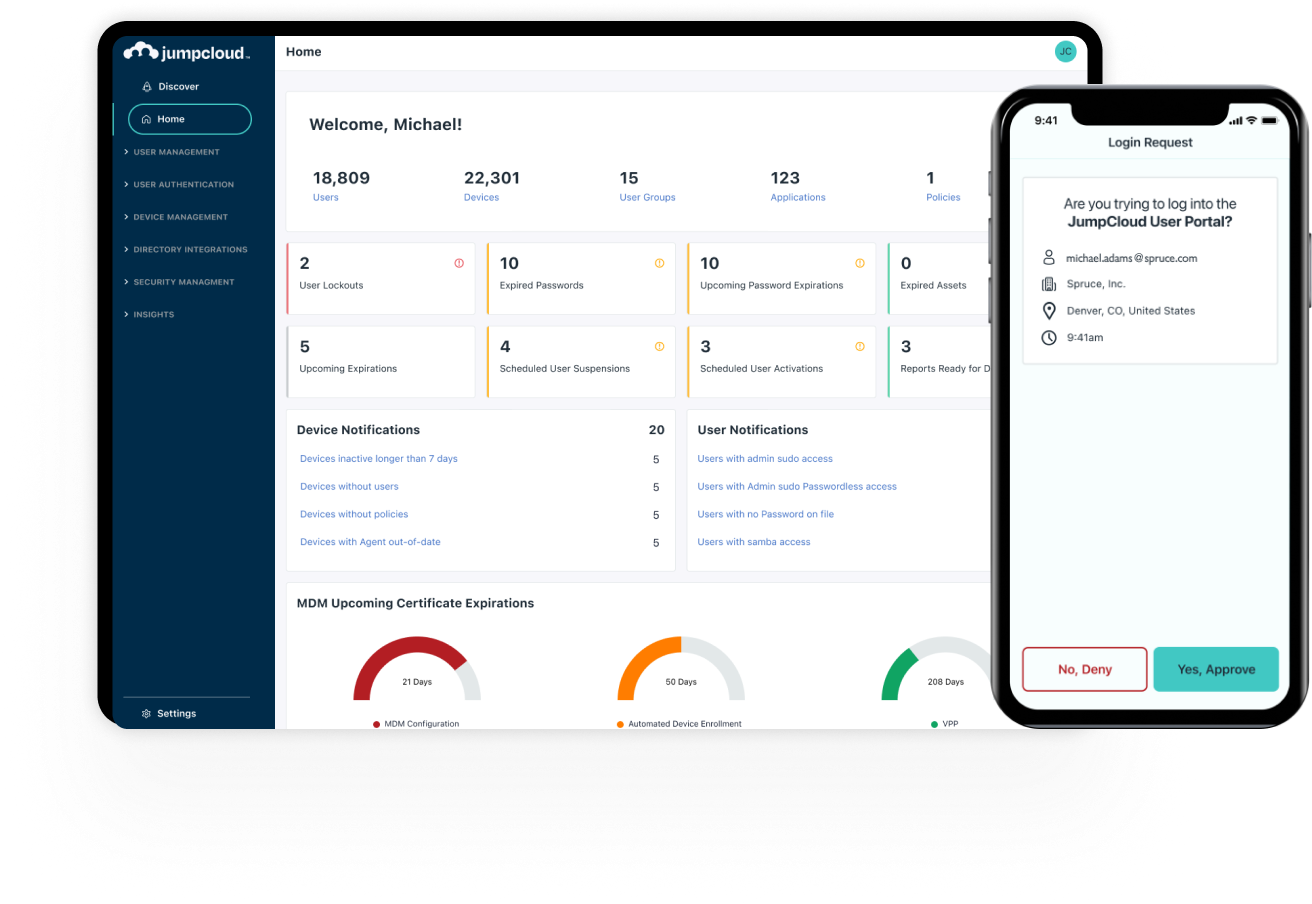
TRUSTED BY ORGANIZATIONS WORLDWIDE
What's New
eBook
State of IT 2024: The Rise of AI, Economic Uncertainty, and Evolving Security Threats
Learn MoreWhitepaper
Modernizing Active Directory: Eliminate IT Complexity and Extend Support to Non-Microsoft Resources
Learn MoreTRUSTED BY ORGANIZATIONS WORLDWIDE
JumpCloud Directory Platform
JUMPCLOUD PARTNERS AND INTEGRATES WITH OTHER INDUSTRY-CHANGING ORGANIZATIONS:



Customers recognize the value of JumpCloud.
Don’t take our word for it.